散点图: 主要看数据分布
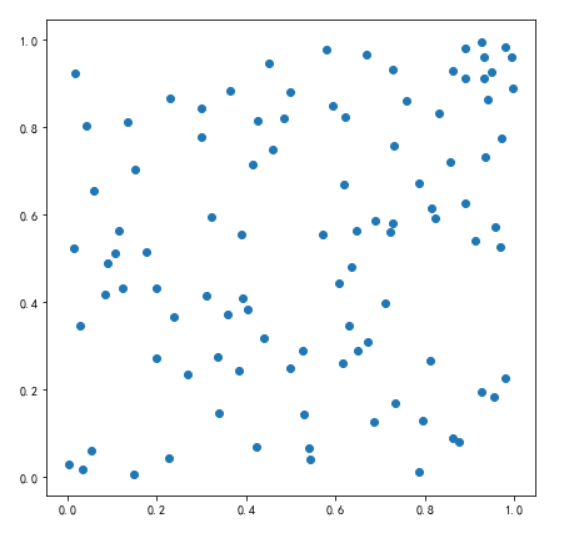
例1: 入门案例, 随机100个点, 观察分布情况
# 散点图,看数据分布
rng = np.random.default_rng(0)
fig = plt.figure(figsize=(7,7))
x = rng.random(100)
y = rng.random(100)
plt.scatter(x,y)
plt.show()
效果如图:
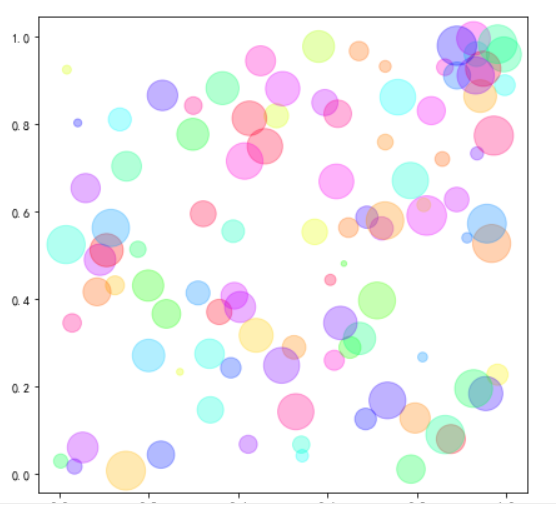
例2: 随机颜色与尺寸
rng = np.random.default_rng(0)
fig = plt.figure(figsize=(7,7))
x = rng.random(100)
y = rng.random(100)
# 随机100种颜色color
c = rng.random(100)
# 定义个size的数组,最小20,最大1000,共100个
s = np.linspace(20,1000,100)
# 散点图,每一个点对应一个随机颜色,每一个点一个尺寸
plt.scatter(x,y,c=c,s=s,alpha=0.3,cmap="hsv")
plt.show()
效果如图:
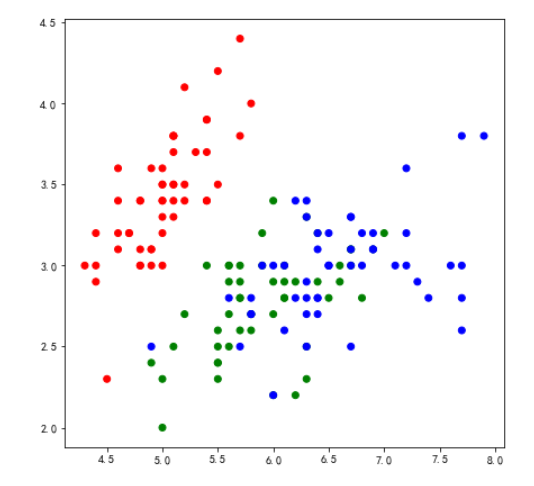
例3: Iris数据集可视化
from sklearn import datasets
# 从sklearn数据集中loadiris,包含三个对象,data,target,target_names
iris = datasets.load_iris()
iris_df = pd.DataFrame(iris.data)
clort_name = ['r','g','b']
colors = [clort_name[i] for i in iris.target]
fig = plt.figure(figsize=(7,7))
plt.scatter(iris_df[0],iris_df[1],c=colors)
plt.show()
效果如图:
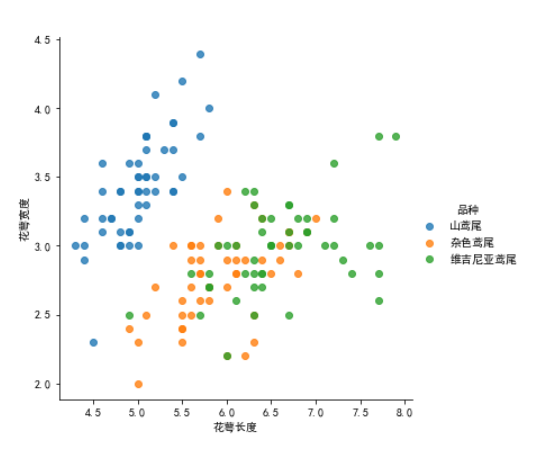
以上是最简的写法(原创), 缺点是没有图示. 如何想列出图示,可以用seaborn
from sklearn import datasets
import seaborn as sns
iris = datasets.load_iris()
feature_name = ['花萼长度','花萼宽度','花瓣长度','花瓣宽度']
iris_df = pd.DataFrame(iris.data, columns=feature_name)
target_name = ['山鸢尾','杂色鸢尾','维吉尼亚鸢尾']
iris_df['品种'] = [target_name[i] for i in iris.target]
sns.lmplot(x='花萼长度', y='花萼宽度',
data=iris_df,hue='品种',fit_reg=False)
效果如图:
留言